

Why Is Kafka Utilized In Real-Time Data Analytics?
In today’s digital world, real-time data analytics and business intelligence insights are becoming increasingly prevalent. Real-time data analytics aids in making timely and relevant judgments. We’ll see why Kafka is utilized for real-time streaming data analytics in this blog post.
What is Kafka?
Kafka is open-source software that allows you to store, read, and analyze streaming data. Kafka is designed to work in a “distributed” setting. Instead of running on a single user’s computer, it runs across multiple (or many) computers, taking advantage of the extra processing power and storage capacity that this provides.
Streaming data is information continuously generated by thousands of data sources, all of which transmit data records simultaneously. A distributed event streaming platform must cope with the constant flow of data and either transform data through either batch – or – real-time processing.
Kafka’s users can take advantage of two primary features:
- Effectively store records streams in the sequence in which they were created.
- Real-time processing of record streams
Kafka is frequently used to build real-time streaming data pipelines and applications that respond to changing data streams. It mixes communications, storage, and stream processing to enable historical and real-time data storage and analysis.
Why would you utilize Kafka?
Kafka is used to develop high-throughput low latency data pipelines. A data pipeline consistently processes and transports data from one system to another, whereas a streaming application consumes data streams. For example, suppose you want to build a data pipeline that uses user activity data to track how people use your website in real-time. In that case, you’d use Kafka to ingest and store streaming data while sending reads to the apps that run the data pipeline. Kafka is also frequently used as a message broker solution, a platform for processing and mediating messages between two applications.
How does Kafka function?
Kafka combines two communications paradigms, queuing and publish-subscribe, to offer customers with the core features of both. Queuing distributes data processing over numerous consumer instances, making it very scalable. Traditional queues, on the other hand, do not allow for multi-subscriber participation. Because every message is delivered to every subscriber, the publish-subscribe strategy cannot be used to distribute work across several worker processes. Kafka uses a partitioned log design to link the two systems together. A log is an ordered sequence of data that are divided into segments, or partitions, that correspond to various subscribers. This implies that several subscribers can be assigned to the same topic, and each is allocated a partition to allow for greater scalability.
Using Kafka for Real-Time Streaming
The producer might be a single web host or web server that broadcasts the data. Data in Kafka is divided into topics. The producer disseminates data on a certain issue.
Businesses frequently use Kafka to build real-time data pipelines because it can extract high-velocity, high-volume data. This high-velocity data is sent through a Kafka real-time pipeline. The published data is subscribed to using any streaming platform, such as Spark, Kafka connector, Node Rdkafka, or Java Kafka connectors, or Elasticsearch sink connector… The subscription data is subsequently published to the dashboard using APIs.
Kafka APIs
- The Admin API – is used to manage and inspect Kafka topics, brokers, and other objects.
- The Producer API – enables you to publish (write) a stream of events to one or more Kafka topics.
- The Consumer API – allows you to subscribe to (read) one or more topics and handle the stream of events sent to them.
- The Kafka Streams API – enables the creation of stream processing applications and microservices. It includes higher-level methods for processing event streams, such as transformations, stateful operations such as aggregations and joins, windowing, event-time processing, and more. Input is read from one or more topics to create output to one or more topics, thus converting input streams to output streams.
- The Kafka Connect API – allows you to create and execute reusable data import/export connectors that ingest (read) or output (write) streams of events from and to external systems and applications so they may interface with Kafka. A connector to a relational database, such as PostgreSQL, could, for example, record every change to a group of tables. In reality, however, you often do not need to create your connections because the Kafka community already provides hundreds of ready-to-use connectors.
Advantage of using Kafka
- Kafka can manage massive amounts of data and is a highly dependable, fault-tolerant, and scalable system.
- Kafka is a distributed publish-subscribe messaging system (the publish-subscribe messaging system in Kafka is termed brokers), making it superior to other message brokers such as JMS, RabbitMQ, and AMQP.
- Unlike JMS, RabbitMQ, and AMQP message brokers, Kafka can handle high-velocity real-time data.
- The message queue in Kafka is persistent. The transmitted data is kept until it has reached the set retention period, which may be a time limit or a size restriction.
- Kafka offers extremely low end-to-end latency for big data volumes. This means the amount of time it takes for a record that is produced to Kafka to be fetched by the consumer is short.
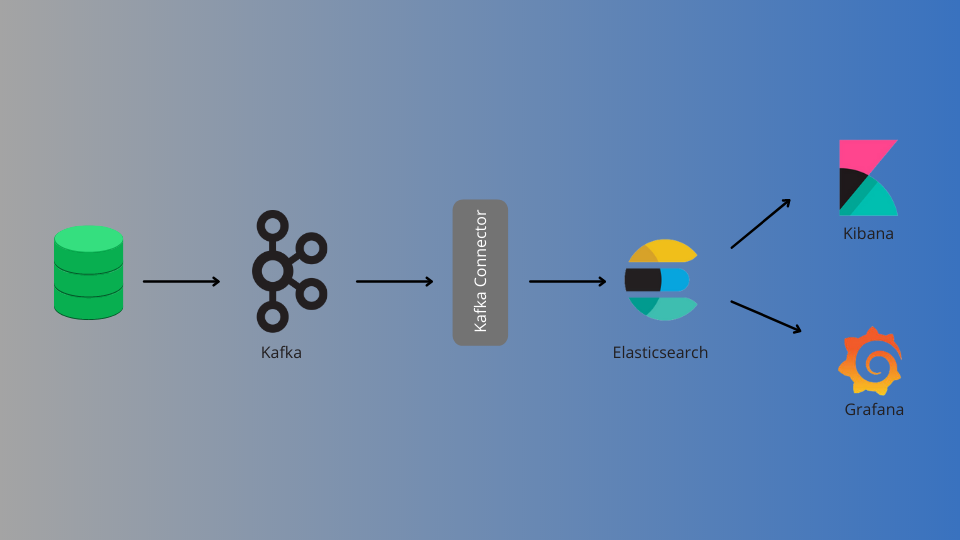
how to migrate data from Kafka to Elasticsearch
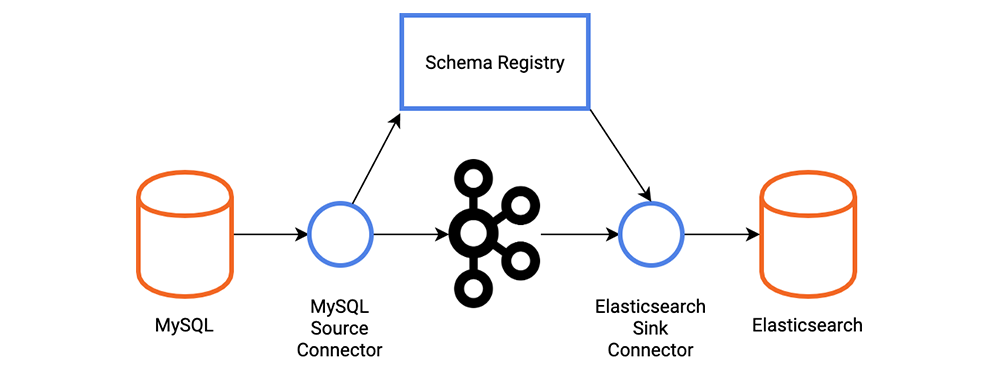
Elasticsearch sink connector, according to Confluent, is the connector that allows you to link Apache Kafka® and Elasticsearch easily. You may stream data from Kafka into Elasticsearch, which can utilize for log analysis or full-text search. Alternatively, you may use this data to do real-time analytics or integrate it with other apps such as Kibana.
The Elasticsearch Service Sink connection includes the following functionality:
Once delivery has occurred
To assure exactly-once delivery to Elasticsearch, the connection depends on Elasticsearch’s idempotent write semantics. The connection may assure precise delivery by assigning IDs to Elasticsearch documents. If keys are supplied in Kafka messages, they are immediately converted to Elasticsearch document IDs. When the keys are not supplied or expressly disregarded, the connector will utilize topic+partition+offset as the key, guaranteeing that each message in Kafka corresponds to precisely one document in Elasticsearch.
The queue for Dead Letters
This connector supports the Dead Letter Queue (DLQ) feature. An invalid record might happen for a variety of reasons. Serialization and deserialization faults are the most common Connect problems.
Several tasks
Elasticsearch Service Sink connection allows you to perform one or more jobs. In the tasks, you may define the number of tasks. The maximum configuration parameter When must process multiple files, this can result in significant efficiency benefits.
Inference mapping
Connect can use schemas to infer mappings by the connector. When enabled, the connection generates mappings based on Kafka message schemas. In the absence of a field, the inference is confined to field types and default values. You should manually develop mappings if extra modifications are needed.
Zen Networks is a leading provider of advanced IT solutions, specializing in log monitoring, automation and DevOps.
Our expert team offers a wide range of services, including IT monitoring, cloud services, agile solutions, and automation. We are also well-versed in the installation and implementation of Elasticsearch, Logstask, and Kibana on Docker.
By leveraging our extensive domain expertise and innovative technologies, we empower our clients to optimize their IT infrastructure and achieve operational excellence. Our solutions are designed to help organizations of all sizes to streamline their processes, improve efficiency, and reduce costs.
We invite you to take advantage of our complimentary consultation and quote service to learn more about how we can help your organization to achieve its IT goals. Contact us now to schedule your consultation and discover the benefits of working with Zen Networks.


