
Pourquoi Kafka est-il utilisé dans l'analyse de données en temps réel ?
Dans le monde numérique d'aujourd'hui, en temps réel données analytics et les informations sur l'intelligence d'affaires deviennent de plus en plus répandues. Données en temps réel analytics aide à rendre des jugements opportuns et pertinents. Nous verrons pourquoi Kafka est utilisé pour le streaming en temps réel données analytics dans ce blog poster.
Qu'est-ce que Kafka?
Kafka est un logiciel open source qui vous permet de stocker, de lire et d'analyser des données de streaming. Kafka est conçu pour fonctionner dans un cadre « distribué ». Au lieu de fonctionner sur l'ordinateur d'un seul utilisateur, il s'exécute sur plusieurs multiple (ou plusieurs) ordinateurs, tirant parti de la puissance de traitement et de la capacité de stockage supplémentaires que cela fournit.
Les données en continu sont des informations générées en continu par des milliers de sources de données, qui transmettent toutes des enregistrements de données simultanément. Une plate-forme de diffusion d'événements distribuée doit faire face au flux constant de données et transformer les données par traitement par lots ou en temps réel.
Les utilisateurs de Kafka peuvent profiter de deux fonctionnalités principales :
- Stockez efficacement les flux d'enregistrements dans l'ordre dans lequel ils ont été créés.
- Traitement en temps réel des flux d'enregistrements
Kafka est fréquemment utilisé pour créer des pipelines et des applications de données en streaming en temps réel qui répondent aux flux de données changeants. Il combine les communications, le stockage et le traitement des flux pour permettre l'historique et données en temps réel à grande vitesse. stockage et analyse.
Pourquoi utiliseriez-vous Kafka ?
Kafka est utilisé pour développer des pipelines de données à haut débit et à faible latence. Un pipeline de données traite et transporte de manière cohérente les données d'un système à un autre, tandis qu'une application de streaming consomme des flux de données. Par exemple, supposons que vous souhaitiez créer un pipeline de données qui utilise les données d'activité des utilisateurs pour suivre la façon dont les gens utilisent votre site Web en temps réel. Dans ce cas, vous utiliseriez Kafka pour ingérer et stocker des données de streaming tout en envoyant des lectures aux applications qui exécutent le pipeline de données. Kafka est également fréquemment utilisé comme solution de courtage de messages, une plate-forme de traitement et de médiation de messages entre deux applications.
Comment fonctionne Kafka ?
Kafka combine deux paradigmes de communication, la mise en file d'attente et la publication-abonnement, pour offrir aux clients les fonctionnalités de base des deux. La mise en file d'attente distribue le traitement des données sur de nombreuses instances de consommateur, ce qui le rend très évolutif. Les files d'attente traditionnelles, en revanche, ne permettent pas la participation de plusieurs abonnés. Étant donné que chaque message est remis à chaque abonné, la stratégie de publication-abonnement ne peut pas être utilisée pour répartir le travail sur plusieurs processus de travail. Kafka utilise une conception de journal partitionné pour relier les deux systèmes. Un journal est une séquence ordonnée de données qui sont divisées en segments, ou partitions, qui correspondent à divers abonnés. Cela implique que plusieurs abonnés peuvent être affectés au même sujet, et chacun se voit attribuer une partition pour permettre une plus grande évolutivité.
Utilisation de Kafka pour le streaming en temps réel
Le producteur peut être un hôte Web ou un serveur Web unique qui diffuse les données. Les données dans Kafka sont divisées en rubriques. Le producteur diffuse des données sur une certaine question.
Les entreprises utilisent fréquemment Kafka pour créer des pipelines données en temps réel à grande vitesse. car il peut extraire des données à grande vitesse et à volume élevé. Ces données à grande vitesse sont envoyées via un pipeline en temps réel Kafka. Les données publiées sont souscrites à l'aide de n'importe quelle plate-forme de streaming, telle que les connecteurs Spark, Kafka, Node Rdkafka ou Java Kafka, ou le connecteur Elasticsearch sink… Les données d'abonnement sont ensuite publiées sur le tableau de bord à l'aide d'API.
API Kafka
- API Admin - est utilisée pour gérer et inspecter les sujets Kafka, les courtiers et d'autres objets.
- API Producteur - vous permet de publier (écrire) un flux d'événements dans un ou plusieurs sujets Kafka.
- API consommateur - vous permet de vous abonner à (lire) un ou plusieurs sujets et de gérer le flux d'événements qui leur sont envoyés.
- API Kafka Streams - permet la création d'applications de traitement de flux et de microservices. Il inclut des méthodes de niveau supérieur pour le traitement des flux d'événements, telles que les transformations, les opérations avec état telles que les agrégations et les jointures, le fenêtrage, le traitement au moment de l'événement, etc. L'entrée est lue à partir d'un ou plusieurs sujets pour créer une sortie vers un ou plusieurs sujets, convertissant ainsi les flux d'entrée en flux de sortie.
- API Kafka Connect - vous permet de créer et d'exécuter des connecteurs d'importation/exportation de données réutilisables qui ingèrent (lisent) ou génèrent (écrivent) des flux d'événements depuis et vers des systèmes et applications externes afin qu'ils puissent s'interfacer avec Kafka. Un connecteur à une base de données relationnelle, telle que PostgreSQL, pourrait, par exemple, enregistrer chaque modification apportée à un groupe de tables. En réalité, cependant, vous n'avez souvent pas besoin de créer vos connexions car la communauté Kafka fournit déjà des centaines de connecteurs prêts à l'emploi.
Avantage de l'utilisation de Kafka
- Kafka peut gérer des quantités massives de données et est un système hautement fiable, tolérant aux pannes et évolutif.
- Kafka est un système de messagerie de publication-abonnement distribué (le système de messagerie de publication-abonnement de Kafka est appelé courtiers), ce qui le rend supérieur aux autres courtiers de messages tels que JMS, RabbitMQ et AMQP.
- Contrairement aux courtiers de messages JMS, RabbitMQ et AMQP, Kafka peut gérer des données en temps réel à grande vitesse..
- La file d'attente de messages dans Kafka est persistante. Les données transmises sont conservées jusqu'à ce qu'elles aient atteint la durée de conservation définie, qui peut être une limite de temps ou une restriction de taille.
- Kafka offre une latence de bout en bout extrêmement faible pour les gros volumes de données. Cela signifie que le temps nécessaire pour qu'un enregistrement produit par Kafka soit récupéré par le consommateur est court.
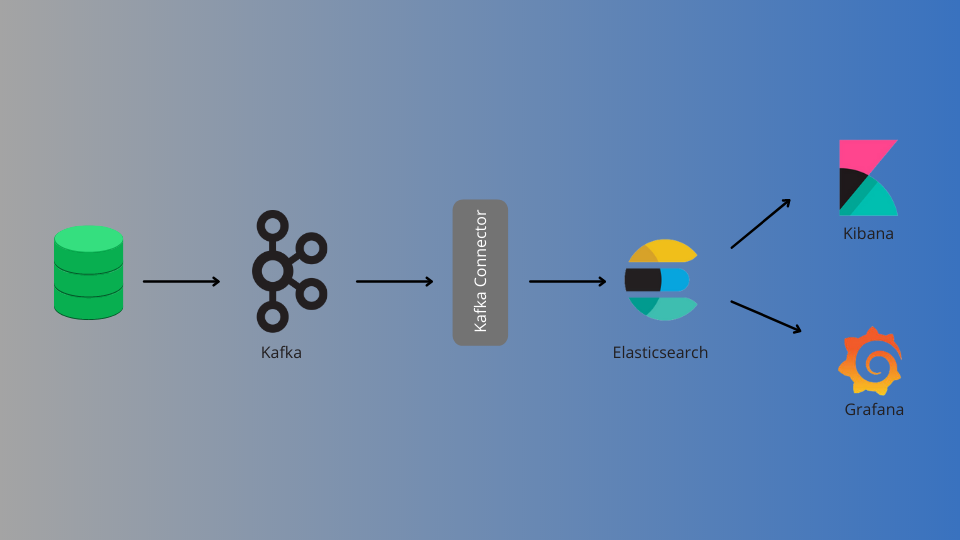
comment migrer des données de Kafka vers Elasticsearch
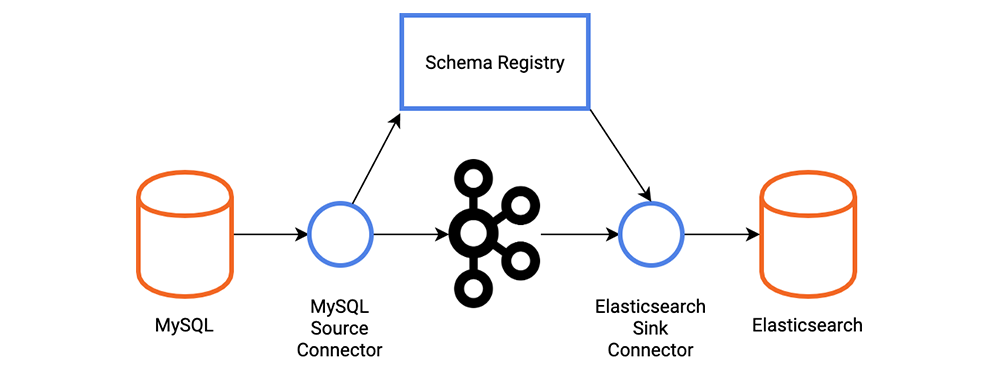
Connecteur de récepteur Elasticsearch, selon Confluent, est le connecteur qui permet de lier Apache Kafka® et ElasticSearch facilement. Vous pouvez diffuser des données de Kafka dans Elasticsearch, qui peut être utilisé pour l'analyse des journaux ou la recherche en texte intégral. Alternativement, vous pouvez utiliser ces données pour faire en temps réel analytics ou intégrez-le à d'autres applications telles que Kibana.
La connexion Elasticsearch Service Sink inclut les fonctionnalités suivantes :
Une fois la livraison effectuée
Pour assurer une livraison unique à Elasticsearch, la connexion dépend de la sémantique d'écriture idempotente d'Elasticsearch. La connexion peut assurer une livraison précise en attribuant des identifiants aux documents Elasticsearch. Si des clés sont fournies dans les messages Kafka, elles sont immédiatement converties en ID de document Elasticsearch. Lorsque les clés ne sont pas fournies ou sont expressément ignorées, le connecteur utilise topic+partition+offset comme clé, garantissant que chaque message dans Kafka correspond précisément à un document dans Elasticsearch.
La file d'attente des lettres mortes
Ce connecteur prend en charge la fonction Dead Letter Queue (DLQ). Un enregistrement invalide peut se produire pour diverses raisons. Les erreurs de sérialisation et de désérialisation sont les problèmes de connexion les plus courants.
Plusieurs tâches
La connexion Elasticsearch Service Sink vous permet d'effectuer une ou plusieurs tâches. Dans les tâches, vous pouvez définir le nombre de tâches. Le paramètre de configuration maximal Quand doit traiter plusieurs fichiers, cela peut entraîner des gains d'efficacité significatifs.
Cartographie d'inférence
Connect peut utiliser des schémas pour déduire des mappages par le connecteur. Lorsqu'elle est activée, la connexion génère des mappages basés sur les schémas de message Kafka. En l'absence de champ, l'inférence est limitée aux types de champ et aux valeurs par défaut. Vous devez développer manuellement les mappages si des modifications supplémentaires sont nécessaires.
Zen Networks est un fournisseur leader de solutions informatiques avancées, spécialisé dans log monitoring, automatisation et DevOps.
Notre équipe d'experts propose une large gamme de services, y compris l'informatique monitoring, services cloud, solutions agiles et automatisation. Nous connaissons également bien l'installation et la mise en œuvre d'Elasticsearch, Logstask et Kibana sur Docker.
En tirant parti de notre vaste expertise dans le domaine et de nos technologies innovantes, nous permettons à nos clients d'optimiser leur infrastructure informatique et d'atteindre l'excellence opérationnelle. Nos solutions sont conçues pour aider les organisations de toutes tailles à rationaliser leurs processus, à améliorer leur efficacité et à réduire leurs coûts.
Nous vous invitons à profiter de notre service de consultation et de devis gratuit pour en savoir plus sur la manière dont nous pouvons aider votre organisation à atteindre ses objectifs informatiques. Contact contactez-nous maintenant pour planifier votre consultation et découvrir les avantages de travailler avec Zen Networks.


