

Déploiement d'un APM basé sur Kubernetes (Prt2)
Les phases de mise en œuvre de l'application APM basée sur Kubernetes
Cette deuxième partie traite de la phase de conception et de mise en œuvre de la solution basée sur Kubernetes et de ses détails. Nous verrons comment fonctionne le Déploiement d'un APM sur Kubernetes d'une autre manière nous verrons comment instrumenter un programme Go pour qu'il émette des traces conformes à OpenTelemetry, ainsi que comment transférer ces traces vers Elastic APM comprenant kubernetes.
Présentation de l'architecture OpenTelemetry
Il est nécessaire de comprendre l'architecture de OpenTélémétrie avant de plonger dans les subtilités de l'instrumentation des applications. Les récepteurs, les exportateurs et les collecteurs sont les blocs de construction fondamentaux.
Il existe d'autres protocoles parmi lesquels choisir, mais le plus répandu est OTLP. Les exportateurs fonctionnent de la même manière qu'une API, encapsulant les spécificités de la livraison des données à un certain backend. Pour créer un pipeline de traitement, tel que la préparation des données à envoyer vers une ou plusieurs destinations, les collecteurs s'appuient sur un ensemble de destinataires et d'exportateurs. Le schéma ci-dessous illustre cette architecture.
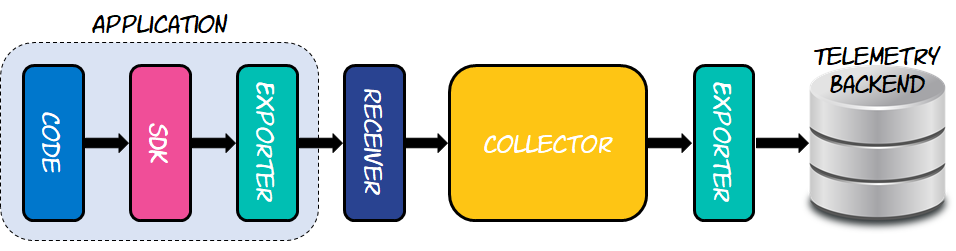
Parce qu'il doit pouvoir envoyer les traces produites au collecteur, le programme instrumenté, comme indiqué sur la figure, comporte au moins un des éléments de construction, qui sont des exportateurs. Le collecteur réside entre l'application instrumentée et le backend de télémétrie, qui sera Elastic APM pour les besoins de cet article. Pour accepter les traces délivrées par l'application instrumentée, le collecteur doit disposer d'un récepteur. De même, comme la collection ne sait pas comment envoyer des données à Elastic APM, elle emploie un exportateur qui s'en charge. Cela permet au collectionneur d'apprendre comment la technologie fonctionne.
L'architecture OpenTelemetry, qui se concentre sur les récepteurs, les exportateurs et les collecteurs, permet aux utilisateurs de mélanger et d'adapter différents protocoles et technologies, leur donnant la liberté de choisir plusieurs fournisseurs sans perdre la compatibilité. Cela implique que vous pouvez créer votre programme pour générer des traces compatibles avec OpenTelemetry pendant le développement, puis passer à un backend de télémétrie différent (idéalement Elastic APM ) une fois qu'il est prêt pour la production.
Configuration de la Elastic stack sur kubernetes
Élastique APM tilise Elasticsearch pour stocker les données et Kibana pour les visualiser.
elasticsearch.yaml
# elasticsearch.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
spec:
selector:
matchLabels:
app: elasticsearch
replicas: 1
template:
metadata:
name: elasticsearch
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:7.13.2
env:
- name: "discovery.type"
value: "single-node"
ports:
- name: es-9200
containerPort: 9200
imagePullPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
labels:
app: elasticsearch s
pec:
type: NodePort
ports:
- name: es-9200
port: 9200
selector:
app: elasticsearch
---Kibana.yaml
#Kibana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
spec:
selector:
matchLabels:
app: kibana
replicas: 1
template:
metadata:
name: kibana
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.13.2
env:
- name: "ELASTICSEARCH_URL"
value: "127.0.0.1:9200"
ports:
- name: kibana-5601
containerPort: 5601
imagePullPolicy: Never
---
apiVersion: v1
kind: Service
metadata:
name: kibana
labels:
app: kibana
spec:
type: NodePort
ports:
- name: kibana-5601
port: 5601
selector:
app: kibana
---
apm-serveur.yaml
#apm-server.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: apm-server
spec:
selector:
matchLabels:
app: apm-server
replicas: 1
template:
metadata:
name: apm-server
labels:
app: apm-server
spec:
containers:
- name: apm-server
image: docker.elastic.co/apm/apm-server:7.13.2
env:
- name: "STORAGE_TYPE"
value: "elasticsearch"
- name: "ES_HOST"
value: "127.0.0.1:9200"
- name: "kibana_HOST"
value: "127.0.0.1:5601"
ports:
- name: apm-server-8200
containerPort: 8200
imagePullPolicy: Never
---
apiVersion: v1
kind: Service
metadata:
name: apm-server
labels:
app: apm-server
spec:
type: NodePort
ports:
- name: apm-server-8200
port: 8200
selector:
app: apm-server
---Nous déployons Elasticsearch, kibana et Elastic Apm dans l'espace de noms par défaut du même cluster Kubernetes .
kubectl apply -f./Elastickubectl port-forward service/elasticsearch 9200kubectl port-forward service/kibana 5601kubectl port-forward service/apm-server 8200Implémentation d'un collecteur
Le collecteur est un composant important de la conception car il sert de middleware qui connecte l'application instrumentée au backend de télémétrie.
Utilisez YAML pour tout personnaliser. Par conséquent, construisez un fichier YAML avec le contenu suivant :
---
apiVersion: v1
kind: ConfigMap
metadata:
name: otel-collector-config
data:
config.yaml: |-
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:55680
http:
endpoint: 0.0.0.0:55681
hostmetrics:
collection_interval: 1m
scrapers:
cpu:
load:
memory:
processors:
batch: null
exporters:
elastic:
apm_server_url: 'http://apm-server:8200'
logging:
loglevel: DEBUG
extensions:
service:
pipelines:
metrics:
receivers:
- otlp
- hostmetrics
exporters:
- logging
- elastic
traces:
receivers:
- otlp
processors:
- batch
exporters:
- elastic
- logging
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
labels:
app: opentelemetry
component: otel-collector
spec:
selector:
matchLabels:
app: opentelemetry
component: otel-collector
template:
metadata:
labels:
app: opentelemetry
component: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib-dev:latest
imagePullPolicy: Never
resources:
limits:
cpu: 100m
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- mountPath: /var/log
name: varlog
readOnly: true
- mountPath: /var/lib/docker/containers
name: varlibdockercontainers
readOnly: true
- mountPath: /etc/otel/config.yaml
name: data
subPath: config.yaml
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: data
configMap:
name: otel-collector-config
---
apiVersion: v1
kind: Service
metadata:
name: otel-collector
labels:
app: opentelemetry
component: otel-collector
spec:
ports:
- name: metrics # Default endpoint for querying metrics.
port: 8888
- name: grpc # Default endpoint for OpenTelemetry receiver.
port: 55680
protocol: TCP
targetPort: 55680
- name: http # Default endpoint for OpenTelemetry receiver.
port: 55681
protocol: TCP
targetPort: 55681
selector:
component: otel-collectorconfigurez un récepteur pour le protocole OTLP, et il s'attend à recevoir des données via le port 55680 à partir de n'importe quelle interface réseau. Les traces seront envoyées à cet endpoint par l'application instrumentée. Une extension est également configurée pour permettre à n'importe quelle couche de supervision en aval d'effectuer des vérifications de l'état du collecteur. Les vérifications de l'état sont effectuées par défaut via HTTP sur le port 13133. Enfin, le collecteur envoie les données au point de terminaison http://apm-server:8200 à l'aide de l'exportateur intégré d'Elastic APM. Pour que cela fonctionne, Elastic APM doit être disponible pour cette URL.
Nous déployons le collecteur dans le même cluster kubernetes qu'avant :
kubectl apply -f otel-config.yamlkubectl port-forward service/otel-collector 55680:55680 55681:55681 -n defaultInstrumentation d'application
L'objectif de ce projet est de déployer une solution de supervision des performances APM depuis n'importe quelle application. L'application suivante est un microservice Go qui envoie des traces et des métriques au collecteur à l'aide de Opentelemetry.
# main.go
package main
import (
"context"
"encoding/json"
"log"
"net/http"
"os"
"runtime"
"time"
"github.com/gorilla/mux"
"go.opentelemetry.io/contrib/instrumentation/github.com/gorilla/mux/otelmux"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/attribute"
"go.opentelemetry.io/otel/exporters/otlp"
"go.opentelemetry.io/otel/exporters/otlp/otlpgrpc"
"go.opentelemetry.io/otel/metric"
"go.opentelemetry.io/otel/metric/global"
"go.opentelemetry.io/otel/propagation"
controller "go.opentelemetry.io/otel/sdk/metric/controller/basic"
processor "go.opentelemetry.io/otel/sdk/metric/processor/basic"
"go.opentelemetry.io/otel/sdk/metric/selector/simple"
"go.opentelemetry.io/otel/sdk/resource"
sdktrace "go.opentelemetry.io/otel/sdk/trace"
"go.opentelemetry.io/otel/semconv"
"go.opentelemetry.io/otel/trace"
)
const (
serviceName = "hello-app"
serviceVersion = "1.0"
metricPrefix = "custom.metric."
numberOfExecName = metricPrefix + "number.of.exec"
numberOfExecDesc = "Count the number of executions."
heapMemoryName = metricPrefix + "heap.memory"
heapMemoryDesc = "Reports heap memory utilization."
)
var (
tracer trace.Tracer
meter metric.Meter
numberOfExecutions metric.BoundInt64Counter
)
func main() {
ctx := context.Background()
// Create an gRPC-based OTLP exporter that
// will receive the created telemetry data
endpoint := os.Getenv("0.0.0.0:55680")
driver := otlpgrpc.NewDriver(
otlpgrpc.WithInsecure(),
otlpgrpc.WithEndpoint(endpoint),
)
exporter, err := otlp.NewExporter(ctx, driver)
if err != nil {
log.Fatalf("%s: %v", "failed to create exporter", err)
}
// Create a resource to decorate the app
// with common attributes from OTel spec
res0urce, err := resource.New(ctx,
resource.WithAttributes(
semconv.ServiceNameKey.String(serviceName),
semconv.ServiceVersionKey.String(serviceVersion),
),
)
if err != nil {
log.Fatalf("%s: %v", "failed to create resource", err)
}
// Create a tracer provider that processes
// spans using a batch-span-processor. This
// tracer provider will create a sample for
// every trace created, which is great for
// demos but horrible for production –– as
// volume of data generated will be intense
bsp := sdktrace.NewBatchSpanProcessor(exporter)
tracerProvider := sdktrace.NewTracerProvider(
sdktrace.WithSampler(sdktrace.AlwaysSample()),
sdktrace.WithResource(res0urce),
sdktrace.WithSpanProcessor(bsp),
)
// Creates a pusher for the metrics that runs
// in the background and push data every 5sec
pusher := controller.New(
processor.New(
simple.NewWithExactDistribution(),
exporter,
),
controller.WithResource(res0urce),
controller.WithExporter(exporter),
controller.WithCollectPeriod(5*time.Second),
)
err = pusher.Start(ctx)
if err != nil {
log.Fatalf("%s: %v", "failed to start the controller", err)
}
defer func() { _ = pusher.Stop(ctx) }()
// Register the tracer provider and propagator
// so libraries and frameworks used in the app
// can reuse it to generate traces and metrics
otel.SetTracerProvider(tracerProvider)
global.SetMeterProvider(pusher.MeterProvider())
otel.SetTextMapPropagator(
propagation.NewCompositeTextMapPropagator(
propagation.Baggage{},
propagation.TraceContext{},
),
)
// Instances to support custom traces/metrics
tracer = otel.Tracer("io.opentelemetry.traces.hello")
meter = global.Meter("io.opentelemetry.metrics.hello")
// Creating a custom metric that is updated
// manually each time the API is executed
numberOfExecutions = metric.Must(meter).
NewInt64Counter(
numberOfExecName,
metric.WithDescription(numberOfExecDesc),
).Bind(
[]attribute.KeyValue{
attribute.String(
numberOfExecName,
numberOfExecDesc)}...)
// Creating a custom metric that is updated
// automatically using an int64 observer
_ = metric.Must(meter).
NewInt64ValueObserver(
heapMemoryName,
func(_ context.Context, result metric.Int64ObserverResult) {
var mem runtime.MemStats
runtime.ReadMemStats(&mem)
result.Observe(int64(mem.HeapAlloc),
attribute.String(heapMemoryName,
heapMemoryDesc))
},
metric.WithDescription(heapMemoryDesc))
// Register the API handler and starts the app
router := mux.NewRouter()
router.Use(otelmux.Middleware(serviceName))
router.HandleFunc("/hello", hello)
http.ListenAndServe(":8888", router)
}
func hello(writer http.ResponseWriter, request *http.Request) {
ctx := request.Context()
ctx, buildResp := tracer.Start(ctx, "buildResponse")
response := buildResponse(writer)
buildResp.End()
// Creating a custom span just for fun...
_, mySpan := tracer.Start(ctx, "mySpan")
if response.isValid() {
log.Print("The response is valid")
}
mySpan.End()
// Updating the number of executions metric...
numberOfExecutions.Add(ctx, 1)
}
func buildResponse(writer http.ResponseWriter) Response {
writer.WriteHeader(http.StatusOK)
writer.Header().Add("Content-Type",
"application/json")
response := Response{"Hello"}
bytes, _ := json.Marshal(response)
writer.Write(bytes)
return response
}
// Response struct
type Response struct {
Message string `json:"Message"`
}
func (r Response) isValid() bool {
return true
}L'application peut émettre des étendues qui sont des requêtes HTTP dans ce cas. Ensuite, nous créons une image Docker de cette application à partir de ce Dockerfile
# Dockerfile
FROM golang:latest
WORKDIR /app
COPY . .
RUN go build -o main .
EXPOSE 8888
# Command to run the executable
CMD ["./main"]docker build -t hello-app:latestNous déployons ensuite cette application dans notre cluster.
aapiVersion: apps/v1
kind: Deployment
metadata:
name: hello-app
spec:
replicas: 1
selector:
matchLabels:
app: hello-app
template:
metadata:
name: hello-app
labels:
app: hello-app
spec:
containers:
- name: hello-app
image: hello-app:latest
env:
- name: EXPORTER_ENDPOINT
value: "0.0.0.0:55680"
imagePullPolicy: Never
ports:
- name: hello-app
containerPort: 8888
---
apiVersion: v1
kind: Service
metadata:
name: hello-app
labels:
app: hello-app
spec:
type: Load Balancer
ports:
- name: hello-app
port: 8888
selector:
app: hello-app
-
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: hello-app-ingress
spec:
rules:
- http:
paths:
- path: /hello
backend:
serviceName: hello-app
servicePort: 8888kubectl apply -f app.yamlPour vérifier l'état de la ressource Ingress que vous avez configurée à l'étape précédente, utilisez la commande suivante :
kubectl get ingExécutez la commande suivante pour activer le contrôleur d'entrée NGINX :
minikube addons enable ingress La machine virtuelle de Minikube est accessible au système hôte via une adresse IP qui n'est routable qu'à partir de l'hôte et peut être obtenue à l'aide de la commande minikube ip.
minikube ip Lister toutes les ressources dans un espace de noms avec kubectl get all
kubectl get all 
Implémentation du déploiement Canary
Pour les équipes qui ont établi une approche de livraison continue, les déploiements Canarian sont une pratique solide. Une nouvelle fonctionnalité est d'abord mise à la disposition d'un groupe sélectionné d'utilisateurs via un déploiement Canary. Selon le volume de trafic, la nouvelle fonctionnalité est observée pendant quelques minutes à plusieurs heures, ou juste assez longtemps pour acquérir des données significatives. Si l'équipe découvre une faille, la nouvelle fonctionnalité est rapidement désactivée. Si aucun problème n'est découvert, la fonctionnalité est mise à la disposition de tous les utilisateurs.
Un déploiement Canary convertit une partie de vos utilisateurs en votre propre système d'alerte précoce, idéalement un système tolérant aux bogues. Avant de distribuer votre programme, ce groupe d'utilisateurs trouve les défauts, les fonctionnalités défectueuses et les fonctionnalités non intuitives.
Nous commençons par construire les deux variantes d'image de notre application.
Déploiement Kubernetes avec Canaries
docker build -t hello-app:1.0docker build -t hello-app:2.0Nous déploierons ensuite la version 2.0 de notre application
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-app-v1
spec:
replicas: 1
selector:
matchLabels:
app: hello-app
template:
metadata:
name: hello-app
labels:
app: hello-app
spec:
containers:
- name: hello-app-v1
image: hello-app:1.0
env:
- name: EXPORTER_ENDPOINT
value: "0.0.0.0:55680"
imagePullPolicy: Never
ports:
- containerPort: 8888
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-app-v2
spec:
replicas: 1
selector:
matchLabels:
app: hello-app
template:
metadata:
name: hello-app
labels:
app: hello-app
spec:
containers:
- name: hello-app-v2
image: hello-app:2.0
env:
- name: EXPORTER_ENDPOINT
value: "0.0.0.0:55680"
imagePullPolicy: Never
ports:
- containerPort: 8888
---
apiVersion: v1
kind: Service
metadata:
name: hello-app
labels:
app: hello-app
spec:
ports:
- name: hello-app
port: 8888
selector:
app: hello-app
---kubectl apply -f canary-deployment.yamlPour réguler la distribution du trafic, nous aurions besoin de modifier le nombre de répliques dans chaque déploiement.
Cependant, comme nous déployons le service dans un cluster conforme à istio, nous devrons simplement construire une règle de routage pour régir la distribution du trafic.
Par exemple, considérez la règle de routage suivante :
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: hello-app
spec:
hosts:
- hello-app
http:
- route:
- destination:
host: hello-app-v1
weight: 90
- destination:
host: hello-app-v2
weight: 10
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: hello-app
spec:
host: hello-appCet article a fourni un aperçu rapide de OpenTélémétrie et pourquoi il est important pour les applications cloud natives d'aujourd'hui. Vous avez appris à utiliser les outils Go Apps ainsi que leur architecture, ainsi que le déploiement d'un APM. Nous avons précédemment implémenté le déploiement Canary pour réduire les erreurs en veillant automatiquement à ce que l'application soit en cours d'exécution avant sa mise en production. Nous vous recommandons fortement d'explorer OpenTelemetry plus en détail en conjonction avec Elastic APM, qui fournit un excellent support pour les autres piliers de la véritable observabilité du système, tels que les journaux et les métriques.
Si vous n'avez pas vu la 1ère partie du article, cliquez sur le titre suivant : Déploiement d'un APM basé sur Kubernetes (Part1)


